Difference between revisions of "Software architecture notes"
m |
m ({{legacy}}) |
||
| (45 intermediate revisions by 4 users not shown) | |||
| Line 1: | Line 1: | ||
| − | {{ | + | {{legacy}} |
| − | This | + | This specification describes what is required for setting up a [[platform]], an organisation designed to form a network of completely independent nodes with other platforms, which we call the [[platform network]]. The high-level conceptual development path for platform technology is described [[Platform Roadmap|here]]. We will describe our requirements and use cases in order to determine the correct components to use for various aspects. These requirements are based on our research over the past ten years or so regarding what is required for a decentralised, robust and efficient solution to maximise personal empowerment, freedom and privacy and allow for the emergence of bottom-up and grass-roots solutions, and organisations, based on the needs of the people. In our [[manifesto]] we describe the principles and values that guide our work and are foundational to these specifications, in particular the four [[Manifesto#Criteria|criteria]]: |
| + | *Openness | ||
| + | *Completeness | ||
| + | *Think Global, Act Local | ||
| + | *All Aspects Changeable | ||
| + | |||
| + | The document specifies the way to build a powerful and flexible web framework that will empower the vision | ||
| + | |||
| + | The development group requires an independence-focused and philosophically aligned build partner to develop its platform. The development group has elected OD as the ongoing architectural consultants for the development of the development group application. Our initial involvement prior to any funding is to produce a specification document that outlines the work to be done, and the general scope of that work. This document includes that specification and scope of work. This document can also serve as a technical basis for investment pitches to source funding for the process of constructing a more detailed specification and finding developers. We've divided the software aspects of the project into the following four general levels, which can all be developed in parallel, and which clearly delineate the public aspects from those controlled by the development group. | ||
| + | |||
| + | The most important thing to get clear with respect to the business relationship from OD's perspective is that everything we're developing is free, unrestricted open source software licensed under GPL. The aspects not under this license are the development group business rules and branding which are ''content'' in the system, but are not components of the system itself. This specification is focused on the foundation environment inside, upon which the the development group business rules and branding will be built. The section below defines the delineations between OD and the development group more clearly. | ||
| + | |||
| + | '''The foundation environment:''' This is the network application environment. An object-wiki in a peer-to-peer semantic network and a set of foundation objects defining the basic common organisational concepts, relationships and processes. | ||
| + | |||
| + | '''The application interface:''' This is formed from content, such as templates, documentation and processes. It allows everyday users to build, refine, share and collaborate on their documentation and organisational systems. It even allows people to adjust and share their own custom applications in the environment. | ||
| + | |||
| + | ---- | ||
| + | |||
| + | |||
| + | |||
| + | == Overview == | ||
| + | === The Software === | ||
| + | [[File:TheBrain.jpg|right]] This section provides an overview of the software application. We're introducing [http://www.thebrain.com TheBrain] application here because it shares a lot conceptually with the interface we plan to develop, if you're unfamiliar with TheBrain, see [http://blog.thebrain.com/beyond-hierarchies/ this blog post] for a quick introduction to the concept first. | ||
| + | |||
| + | To the right is an image of TheBrain which is essentially a graphical concept and relationship mapping tool. It's very similar to a mindmapping tool, except that it's more node-oriented which allows more intuitive navigation around large complex structures of nodes and for diverse concepts to be connected more easily. | ||
| + | |||
| + | ==== Nodes ==== | ||
| + | The application is focused on one particular node in the network at a time which is always at the centre of the screen. The user can move the focus to other nodes by following the linked relationships. Each node may act as a storage repository for information relating to its concept, for example a node representing a particular idea may contain notes, photos, website links and other related items. | ||
| + | |||
| + | ==== Viewers ==== | ||
| + | The application is like a window, or "viewport" looking into the structure of nodes. The term "viewer" is used to refer to the general class of applications which allow users to view and edit collections of data. The viewer is a tool to provide a window onto the data set and allows the user to look at the data from different perspectives called "views". The idea of moving the "current focus" around the data set (in this case nodes) is a common feature of viewer applications. | ||
| + | |||
| + | Since nodes can be filled with associated content such as text notes and files, it's useful for the viewer application to allow easy switching between a number of different ways of looking at the node currently in focus. For example a "document view" would present the text-based aspects of the current node in a document format, or switching to "file view" the same node would appear as a collection of file attachments in a file-browser like way. | ||
| + | |||
| + | The main point here is that the viewer offers a number of unique views onto the current node which can be switched between at any time. Each view renders particular aspects of the current node and offers navigation methods appropriate to that kind of view for navigating the viewer to other nodes. The nodal view shown in the image of TheBrain to the right is just one view of many that could be added to the viewer application. | ||
| + | |||
| + | ==== Semantic networks & Ontologies ==== | ||
| + | The nodes that make up the data structure in TheBrain are called "thoughts" because the network of relationships is composed completely of the user's own concepts and ideas. In our application, nodes will be objects in the object-oriented (OO) sense, and the relationships connecting nodes together will also be objects making the resulting structure a [[w:Semantic network|semantic network]]. This commonly used structure can be stored or communicated in a wide variety of formats such as OWL which is supported by TheBrain. | ||
| + | |||
| + | If all the nodes in the semantic network are objects, the structure can not only contain arbitrary "thoughts", but also high-level functionality such as processes, tools and interface elements. We will also make use of object-oriented concepts such as inheritance so that objects can be based on others and adjusted for more specific needs. | ||
| + | |||
| + | These semantic structures of objects that offer not only organised information, but also collections of tools with which to access it are called "ontologies". The name "ontology" is used because it concerns reality rather than being just a "taxonomy" which is passive categorisation. | ||
| + | |||
| + | ==== Our ontology ==== | ||
| + | We will create an ontology of content that will form the foundation structure of the network. This will be the initial high-level data set that the viewer application provides access to. We've designed a basic "template organisation" structure. | ||
| + | |||
| + | In any project or organisation the total number of members are always able to be divided into a hierarchy of sub-groups such as departments or roles. This hierarchy is always changing hence we use the term "[[OD:organic_group|organic group]]", because although many of the groupings are very static like the departments and roles, some of them undergo more change, such as members of particular projects or people sharing a common interest. We use the term "ontology" instead of just "hierarchy" or "taxonomy" because this structure of groups reflects the high-level reality of the organisation at any given time. | ||
| + | |||
| + | Each group has it's own home page, or "portal" which is tailored specifically to the needs of its members, firstly by being based on a template appropriate to the type of group it is (such as a department or a project), and secondly because it is easy for members to collaborate on what their portal should look like and which tools and resources should be available to them. Wikipedia's "Enterprise Portal" article is a good place to go for general information about this kind of portal. | ||
| + | |||
| + | Some common tools used by such groups are blogs, forums, wiki pages, mailing lists, group decision-making tools (such as polls), project management tools, shared schedules, resource booking systems and online chat systems. | ||
| + | |||
| + | ==== The workflow interface ==== | ||
| + | [[File:Scratch.gif|right]] We will develop a simple graphical means of defining workflow, we are calling this the 'workflow' view. The 'workflow' view will show sequences of actions separated by intervals or events. An example workflow could be the events occurring as a form is passed around various roles each making changes to the content. This "workflow interface" needs to be simple enough to be used every day by normal users, but complete enough to cover all the organisation's use cases. | ||
| + | |||
| + | ==== Network of groups ==== | ||
| + | We call our semantic structure of objects an ontology because it describes functional systems which will represent real-world processes and resources. We intend for all the running instances of the application to form together into a peer-to-peer network containing a single coherent semantic network of objects. Each running instance of the application will be a viewer onto the single shared data-structure. | ||
| + | |||
| + | This is not to say that all information in the network has to be viewable by all. The idea is that all the peers contribute to the serverless persistent object environment, but users and groups will be able to work with permissions and encryption in the usual ways to have privacy where they need it. | ||
| + | |||
| + | === The Architecture === | ||
| + | Our application requirements are relatively straightforward and could be built simply by extending an existing Content Management System such as Drupal or Plone, since they already have all the functionality we need apart from the workflow interface discussed in the previous section. However, the back-end of this platform has a number of unique features such as self-containment and decentralisation in order to conform to our [[OD:Manifesto|manifesto]], which make these existing platforms inappropriate. | ||
| + | |||
| + | ==== Open ==== | ||
| + | Open source is a set of principles and practices that promote access to the design and production of goods and knowledge<ref>Law professor [http://www.ted.com/index.php/speakers/view/id/223 Yochai Benkler] explains [http://www.ted.com/talks/view/id/247 how collaborative projects] like Wikipedia and Linux represent the next stage of human organization. By disrupting traditional economic production, copyright law and established competition, they’re paving the way for a new set of economic laws, where empowered individuals are put on a level playing field with industry giants.</ref>. The term is most commonly applied to the source code of software that is available to the general public with relaxed or non-existent intellectual property restrictions. This allows users to create software content through incremental individual effort or through collaboration. | ||
| + | |||
| + | The word "open" in the phrase "open source" means much more than simply making the source-code available to the public. It includes the processes involved in collaborating on the source and in implementing and using the end product. When it comes to open source business, the "source code" means the business system and requires a complete definition of all operations of the business and must include the ability to collaborate on that system and allow interested parties to implement and use the same system themselves, and refine it not their specific needs. | ||
| + | |||
| + | ==== Self contained ==== | ||
| + | The core, network and interface need to be [[OD:Self_containment|self contained]], that is, defined in their own terms. The project then evolves from its own tools and can progress effectively due to the reduced need for specialists. | ||
| + | |||
| + | Total self-containment isn't possible currently since the application relies on aspects defined outside of itself, such as the the language it's programmed in and the operating system. Eventually we hope that even these things would be able to be moved into the network and developed from within it, but for this initial phase of development, having just the workflow systems and our own documents, development and project management inside the system is acceptable. | ||
| + | |||
| + | Some technologies support the concept of self-containment more readily than others, for example, the Squeak language and development environment is all defined in it's own objects and syntax. Such technologies are very good candidates for us to use to build our system within even though they are less popular. | ||
| + | |||
| + | ==== Mesh compliant ==== | ||
| + | [[File:Mesh_nodes_overlaid_on_street_map.jpg|250px|right]] | ||
| + | The importance of independent communications is clearly demonstrated by the [http://www.huffingtonpost.com/2011/01/27/egypt-internet-goes-down-_n_815156.html recent events in egypt]<ref>[http://www.huffingtonpost.com/2011/01/27/egypt-internet-goes-down-_n_815156.html Egypt's Internet Shut Down]: A Huffington Post tech enthusiast tried a few tricks to see if Egypt's Internet really was down or it was just server overload causing the problems. He traced IP addresses, particularly for the U.S. Embassy in Cairo which is hosted in Egypt, and found that the Web traffic was indeed being blocked at the country level, not just a simple censoring.</ref>. Having [[w:Wireless mesh network|meshing]] capable applications offers new possibilities for robustness and resilience in communications, but this is discussed in more detail elsewhere. | ||
| + | |||
| + | We don't deal with meshing directly, the point is that our software is able to synchronise changes over whatever transport mechanisms are available whether it be Internet, wireless meshes, point-to-point links or even physical media such as portable hard-drives and memory sticks. | ||
| + | |||
| + | The software needs to be peer-to-peer so that groups can still work together seamlessly even when they are disconnected from the larger network. For example, a group working together in an office which temporarily has an Internet outage could still keep collaborating and communicating effectively without errors. As soon as the network re-establishes itself, all the differences that have accumulated between the local group and the larger network begin synchronising. In the case of conflicting updates, workflows are created amongst the relevant participants so that they will be eventually resolved. | ||
| + | |||
| + | Although this is a more complex infrastructure to design, the result is ultimately more efficient because it eliminates the "rush hour" effect. | ||
| + | |||
| + | == More detail for developers == | ||
| + | === The Software === | ||
| + | ==== The Unified Ontology ==== | ||
| + | A shared and unified network of groups, all having their own extensions of the ontology which together form the unified ontology. Our system includes an initial set of content - content containing thousands of objects such as departments, roles, procedures, and relationships. This provides a unified and immediately useful framework to begin building content into. | ||
| + | |||
| + | ==== The network viewer application ==== | ||
| + | |||
| + | The application: | ||
| + | |||
| + | * is a browser based viewer onto the unified ontology | ||
| + | * has an address (running the browser) that resolves to localhost | ||
| + | * has a standard graphical interface with various views to select the object layer containing personal preferences, toolbars, views menu, content area and probably a navigation area | ||
| + | * has standard MVC style views onto the data structure including text, files, forums, documents, blogs, files, nodal-network (including workflow) | ||
| + | |||
| + | ==== Foundation Ontology ==== | ||
| + | |||
| + | Object Oriented | ||
| + | The network is composed of many instances of the software called "peers", and together all these make up a logical network of nodes that form objects and relationships. The objects have basic object-oriented relationships such as "parent", "sibling", "ancestor", "descendent" etc. | ||
| + | |||
| + | Nodal reduction and events | ||
| + | |||
| + | Instantiation workflows | ||
| + | |||
| + | Collaborative ontology | ||
| + | |||
| + | As per the Organic Design principles, the overall environment will be a "portal ontology" based approach. But there are also a number of lower level classes such as those mentioned above, "job", "task", "activity". To ensure that the ontology is able to scale up to any complexity of organisational system in the future (to allow for our ultimate plan of the people taking large-scale organisation into their own hands), we need to use a proven set of foundation classes. We've chosen to use the ERP5 classes for this since they closely match our own "Nodal Model" but yet also have been extensively proven across many large-scale organisations already. | ||
| + | |||
| + | These five core classes/concepts are Node/Context (such as a person, an organisation, a warehouse, a bank account), Resource (a class/kind of tangible or intangible resource, transferred between Nodes in business processes, e.g. a product, a raw material, a service, cash etc), Movement/Exchange (ordering, deliveries, accounting transactions, payments, manufacturing processes), Item/Record (an instance of Movement), which may have a special identification such as a barcode, an RFID, a subscription, a ticket, etc) and Path/Workflow (a possible Movement that is useful to define trade conditions, supply conditions, payroll models). | ||
| + | |||
| + | ==== The workflow interface ==== | ||
| + | The One Big Voice system involves around twenty different roles each with their own procedures, which results in a complex application. However, when looking more closely at the functional requirements of these procedures, a common pattern emerges. All of them are sequences of events and notifications that could all be described with a common workflow mechanism, reducing most of the application complexity into the domain of content. | ||
| + | |||
| + | Furthermore, when we look at the requirements for the ActionBuilder tool, which is used to define milestones and associated actions, we find that the same workflow interface would be appropriate for this too. The only difference is in the events and actions that should be available in each context. | ||
| + | |||
| + | A graphical nodal system allowing nodes to be arbitrarily created, copied, moved, linked together and contained, would form an excellent basis for a generic workflow interface. These nodes could then be individually selected and set to a pre-defined workflow class, or be refined by allowing events and associated actions to be added, removed or modified. The events and actions available would depend on the context, the class of the node being refined, and on the role of the user. | ||
| + | |||
| + | "Jobs" are instances of workflow classes and should be viewable in the system, each having a "status" property. The status of a job would initially be "pending" if it is created but has requirements such as roles or resources not selected. When all the requirements are satisfied, the status changes to "in progress." When they're complete, their status changes from "in progress" to "completed." They should also be able to be "cancelled" or "on hold." Since workflows can be nested, the job instances should be viewable as a tree. | ||
| + | |||
| + | Project management can be achieved using this workflow system and can be designed like existing effective project management platforms. | ||
| + | |||
| + | ==== Network of groups ==== | ||
| + | |||
| + | A group of people who all trust each other. People can belong to many trust-groups, and all the trust-groups together compose the platform network which is a network formed from trust relationships. Information is able to pass safely and securely between any two people in such a network because the route can be divided up so that information only ever passes between people who trust each other. | ||
| + | |||
| + | Group types - There should be different types of Organic Groups that all work the same way, but have specific layouts and collections of tools. Such types represent the major concepts such as Organisation, Role, Project or Campaign. As well as acting as a container for tools and resources and exhibiting various members, these groups should also have their own data fields and views so that they can be searched for and accessed from various contexts. | ||
| + | |||
| + | Collaboration - The tools that are selected and the way they're laid out should be able to be published as a template option so that it's an available option for others to use. These options should be able to be searched by popularity and other properties so that people can see which portal methodologies are being most widely used within particular contexts. Publishers should be able to include notes about their decisions so that others can make informed decisions when selecting from available options. | ||
| + | |||
| + | Splitting and merging - Groups should be able to divide in separate groups, or merge multiple groups into a single group, as well as be able to create sub-groups. For example if a group decision is unable to be resolved, the group could split into two, or a group representing an organisation may wish to create sub-groups representing various departments and further into projects or roles. Note that roles are a separate concept, but roles may like to have an Organic Group for themselves as a common portal catering to their specific needs. | ||
| + | |||
| + | === The Architecture === | ||
| + | |||
| + | ==== Open ==== | ||
| + | |||
| + | Before a system is able to undergo change through feedback it must first be open. For things to evolve and refine through the scientific method they must be open and reproducible. | ||
| + | |||
| + | ==== Self contained ==== | ||
| + | A self contained system is simply one that can be developed and improved from within itself. Being reliably complete and independent it can be deployed as a package that's ready to install and operate fully. This self contained system, functioning even while isolated from other networks, can grow, expand and deploy it's own system to form new groups. This is achieved in practice through the availability of software packages containing the system that can run on any device, such a tablets, smart phones or laptop computers. | ||
| + | |||
| + | Members can deploy the system for new groups without needing any information from outside their own group, because the entire system is locally available in every implementation, and can be cloned easily onto standard media. | ||
| + | |||
| + | Self containment includes features such as; | ||
| + | |||
| + | *All aspects are changeable using collaborative processes. | ||
| + | *Easy deployment since all the necessary build and education tools are included. | ||
| + | ===== Organisational Model ===== | ||
| + | A system for project management, time accounting and invoicing, communications and scheduling are formed from a collection of workflows (both applicational and human processes) involving the foundation ontology classes. These aspects are all done the standard ways using the usual objects/forms and protocols. | ||
| + | |||
| + | One important aspect in which our organisational model differs is in the utilisation of a generic scalable way of dealing with resources. If people are using the system to specify everything's where-when, then there should be a generic method of multiplexing that work onto the transport system. This same method could apply to files over TCP, or to the movement of physical items in bags and cars. The first step is in assessing the workload and then deciding how it should be distributed across schedules and routes. | ||
| + | |||
| + | ==== Mesh network ==== | ||
| + | |||
| + | ===== Querying and Job execution ===== | ||
| + | To avoid potential flooding of the network with query requests from many peers, queries need to be thought about in a different way. Think of a query as being created in a portal by the subscribers to the portal, and being the result of a workflow which requires the input of each member before it can obtain a result. The query is given an "update cycle" and then all members are required to make their updates to the result before the next update cycle. The published result of the query always remains the same until the end of the update cycle. | ||
| + | |||
| + | Workflows can be scheduled such that all members will make their updates at different times that are distributed evenly over the update cycle period. This principle can work just as well for internal queries that involve classes and instances rather than real members; each class acts like a portal of information shared and collaborated on by its instances. When lists of members or instances become too large, a natural division by region should occur with larger regions having larger update cycles, and having the smaller regions as their member instances. | ||
| + | |||
| + | Queries done in this way require all the possible resulting instances to add an event. This raises potential permission issues, so needs to be handled with care. An application can use energy from all the peers that instantiate it, but the information the application can make use of within those instances is determined by permissions. In the case of One Big Voice, the queries created in the site itself would only involve One Big Voice properties, and One Big Voice would set the permissions of properties it creates even those in the context of user objects. The One Big Voice application would ensure that a useful range of aggregated and state-based information be available to user queries and tools like the ActionBuilder. | ||
| + | |||
| + | Queries that are built within specific groups portals or in the context of a campaign can make use of already available statistics and state information, but any new queries they create that require instantiation of events cannot be made on spaces outside their own context. In other words, members of a group can only make queries that have results that are objects within that group. To go beyond requires that only existing available query results be used. | ||
| + | |||
| + | Queries of this type are actually regular reporting jobs. This principle applies to all kinds of jobs as long as they are ''linearisable'' which means that they can be broken up into an arbitrary number of equal portions of work. In the same way that all the members of a query are scheduled to make their contribution to the result before the next update cycle, so could members also be delivered a package of work needing to be completed and results filed within a specified window of time. | ||
| + | |||
| + | The workload for a context increases in proportion to the number of instances, because every member or user of a context supports an instance of that context. This means that the ability to perform work increases along with it and as a result the network always stays in balance. | ||
| + | |||
| + | This method of job distribution can scale up to human process too, such as painting signs prior to a march. | ||
| + | |||
| + | == The Build == | ||
| + | We will pursue a development approach that involves us implementing these specifications with a team of developers and managing that team to achieve the milestones listed below. Once Organic Design has had the Development specification signed off by One Big Voice and funding has been secured, we will begin a process of identifying suitable development teams and soliciting proposals from those teams for implementing the specification. The methodology we will use for implementation and the milestones for development are outlined below. | ||
| + | |||
| + | === Team and Technology Selection === | ||
| + | This process also includes identifying and interviewing teams of developers (Request for Proposals - RFP), who will submit proposals for how they intend to meet the development milestones and how much they will charge for the milestones outlined here. Therefore we will satisfy two goals at once, the selection of a team and the completion of the specification document, using the feedback of the developers to evolve it. | ||
| + | |||
| + | The selection of an effective project management framework and establishing appropriate PM processes and documentation in preparation for the development work beginning is the second key part of this project. It makes sense to review and test, select and then customise the project management framework as the document is brought to a code-ready state with the assistance of the feedback from developer teams. The test of how successful this process has been is whether it is possible to fully contain the milestones and processes being discussed in the specification document within a functioning system that can support a project team's development activities. | ||
| + | |||
| + | We are assessing a number of suitable development platforms. These will support the Agile methodology in general and fulfill our more specific requirements, such as accounting for time and cost. | ||
| + | |||
| + | ==== Issues affecting the Technology Decision ==== | ||
| + | '''Workflow:''' The development time will be greatly reduced if we can select a technology that strongly supports the workflow paradigm since the majority of our application is workflow oriented. | ||
| + | |||
| + | '''Peer-to-peer:''' It's imperative that the system be running in a peer-to-peer architecture by the time it starts gaining popularity since many campaigns in the system will be very controversial and the risk of the system being shut down may force us to compromise on our agenda-free stance. Conversely if at the time these threats become apparent we have a critical mass in peer-to-peer space it will cause the system to gain popularity even faster if we can report such threats to the members and show them how to spread the peer-to-peer accessibility. | ||
| + | |||
| + | The technology selection phase should be looking closely at each candidate technology's ability to work in the peer-to-peer space. So far only Squeak and Java are the only two environments we've found that have complex applications running in a truly peer-to-peer space, and we have a strong aversion to using Java for a number of reasons, both technological and philosophical. | ||
| + | |||
| + | '''Prototype:''' If we decide that a fully peer-to-peer model is going to take longer than six months to develop to a level of initial usability, then we'll need to seriously consider the development of a prototype system in an environment that allows us to get up and running more quickly. | ||
| + | |||
| + | '''Migration:''' If we were to go with a prototype system first, then we have to ensure that we are developing a migration scheme along with the peer-to-peer system as we develop it. | ||
| + | |||
| + | '''Scalability:''' The architecture needs to ensure that the system can scale indefinitely. Part of this involves ensuring an independent reproducible aspect to the system so that different regions can be managing their own affairs and be responsible for their own resource. If the system is fully peer-to-peer, then scalability shouldn't be an issue and such regional (and also class-based) partitioning will be inherent. But if we go the route of developing a non peer-to-peer prototype system first, then even this must scale reasonably well. Our research has shown that Drupal is capable of scaling well enough, and can be handled as it's needed. | ||
| + | |||
| + | ==== Developer conversations ==== | ||
| + | We have started discussion threads in a number of developer mailing lists to get an idea of how the development teams behind some different candidate technologies felt about our project and how their technologies fit in with it. We have already contacted developers to ask them about certain facets of the development work. They are contributors to the following projects: Joomla, Drupal, Plone, Zope, ZODB, NEO, OpenCobalt, Squeak, Seaside, Pier. | ||
| + | |||
| + | ---- | ||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| + | == Personal Platform == | ||
| + | Beginning with the relevance to the individual, the platform is a software package that enables the user to organise his or her own life, to maintain an overview of goals, values, tasks and commitments, much as described by the [[GTD]] movement, for personal organisation. In addition, we require communications tools and common office productivity software such as email and schedule, web browser and an office suite. These needs are rounded off by online private and secure file storage services to ensure backup of vital data and synchronisation across multiple devices. | ||
| + | |||
| + | === This can all be done now... === | ||
| + | Now these things taken individually are nothing special, anyone can choose to set up a computer with a free or paid-for operating system, such as Linux, Apple or even Windows, then install free or paid-for applications to achieve office productivity and personal organisation requirements, followed by setting up online user accounts to access services and even applications in the "cloud". However, there are a number of limitations that become The development groupious when currently trying to fulfil even these basic personal requirements using off-the-shelf software available on the market today. Without going into full detail, the key issues are: | ||
| + | ==== Fragmentation of data and user accounts ==== | ||
| + | |||
| + | {| | ||
| + | |-valign="top" | ||
| + | |[[File:Social-media-fragmentation.png|500px]] | ||
| + | |''This toolbar along the bottom of a blog article allows people to share the information using their favourite service, possibly several services. Each of these services would have a separate log in and separate data such as user profiles that will need to be kept up to date.'' | ||
| + | |} | ||
| + | ==== Restriction of freedom and loss of data privacy ==== | ||
| + | |||
| + | {| | ||
| + | |-valign="top" | ||
| + | |[[File:I-agree.gif|500px]] | ||
| + | |''Who has time to read through all that boring legalese, just to set up an account or install some software? Unfortunately it turns out that some terms and conditions are anything but reasonable, claiming ownership and perpetual use of all of the data you upload or share on that service.'' | ||
| + | *[[W:Information_privacy|Wikipedia:Information privacy]] | ||
| + | *[http://meedabyte.wordpress.com/2010/05/25/interviewing-richard-stallman-freedom-in-the-time-of-saas/ Interviewing Richard Stallman: Freedom in the time of SaaS] | ||
| + | |} | ||
| + | ==== Having to pay for proprietary software ==== | ||
| + | |||
| + | {| | ||
| + | |-valign="top" | ||
| + | |[[File:Pricing-plan.png|500px]] | ||
| + | |''Use a lot of online services? Those costs can add up, not to mention being prohibitively expensive in so-called "emerging markets".'' | ||
| + | |} | ||
| + | ==== Lack of offline synchronisation with most cloud services ==== | ||
| + | |||
| + | {| | ||
| + | |-valign="top" | ||
| + | |[[File:Server not found.jpg|500px]] | ||
| + | |''Got no Internet? Tough, if your e-life is in the cloud. Most services don't allow for easy offline synchronisation.'' | ||
| + | |} | ||
| + | |||
| + | ==== Freedom in The Cloud ==== | ||
| + | |||
| + | {| | ||
| + | |-valign="top" | ||
| + | |{{#ev:youtube|QOEMv0S8AcA|720}} | ||
| + | |For more information, mainly on the aspect of privacy and the impact of the centralisation of data on our freedom, view [[W:Eben Moglen|Eben Moglen]]'s talk that inspired the creation of a unified, private open source alternative to Facebook and similar services: [http://www.joindiaspora.com/ Diaspora]. | ||
| + | |} | ||
| + | |||
| + | === What we want instead === | ||
| + | In contrast, what platform offers is an integrated, consistent user interface, with the context being navigated comprising the users areas of interest and personal projects, rather than fragmented applications. We envisage a fully packaged installation file (ISO) that allows an operating system to be set up from scratch on any device, offering a web browser interface to allow the user to define their areas of interest and projects, import legacy data and access any applications as required to do work or just socialise online. | ||
| + | |||
| + | The Platform is a self-contained solution that could for instance run on a laptop, whether or not there is Internet available, which could fetch updates, messages or files as and when connectivity is available. Imagine having one place from which everything is managed, messages and updates are sent from, a private, secure online home with a unified inbox, set of files, bookmarks, documents, contacts, to be easily shared, in a system that just works and is completely self-contained. | ||
| + | |||
| + | The good news is that this is all possible now, by way of integrating existing open source technologies using the right kind of "glue". Further on we will identify our current candidates for fulfilling various aspects described here. | ||
| + | |||
| + | == Platform Organisation == | ||
| + | |||
| + | |||
| + | Note to be worked on: | ||
| + | |||
| + | Provides easy to use function to share video and audio media that provides education about deploying and growing the seed. Media can be tagged in the wiki record, to offer a thumbnail view to relevant shorter media clips. This provides a tag-able, contextualized sharing of media section-by-section. | ||
| + | |||
| + | The platform media library becomes micro-clipped, tagged and able to be be used and shared at a very granular level throughout all platform communications. | ||
| + | |||
| + | == One tree that holds it all together == | ||
| + | The framework platform is based upon can be thought of as a "glue" that integrates a number of existing technologies and allows new technologies to be integrated as they become available. At the interface level, a tree represents the ontology of the user or organisation being viewed. This tree is a meaningful and coherent structure that represents a small number of top-level concepts. The tree will be different when looking at one's personal "electronic life representation", in which case it consists of "[[areas of focus]]" in life, as opposed to viewing a shared organisational tree. David Allen coined that term and recommends having a perspective on life (20.000ft) at which only these areas of focus are visible in order to assess how much time one is spending in different areas and whether they are in balance. This area is in between the most high-level aspects, such as [[goals]], [[vision]] and [[values]] and the more concrete day-to-day aspects such as projects, checklists and tasks, which would typically be associated with one or more areas of focus. On the level of organisations, this concept maps quite directly to what is normally called a "[[department]]" or "division". | ||
| + | <gallery caption="Some example tree structures for personal organisation and business" widths="440px" heights="350px" perrow="2"> | ||
| + | File:Area of focus tree-David Allen Company.jpg|David Allen, creator of [[GTD]], shows his company "areas of focus"/departments in this tree | ||
| + | File:Personal Organisation Tree-David Allen.jpg|David Allen's [[personal organisation]] areas of focus | ||
| + | File:Personal organisation-tree-mm.jpg|A personal organisation tree done with mindmap software | ||
| + | </gallery> | ||
| + | As you can see from the examples, the structure can be quite simple and encompassing at this level. | ||
| + | |||
| + | Our goal is to enable such a tree to replace any hierarchical navigation structures being used by existing applications, such as the folder trees of email programs, file managers or bookmarking programs. Instead, the personal or group organisation tree will be created once, using a simple, forms based process, then linked to applications. This will then allow one structure to be navigated and added to within a consistent interface, with each area of focus or department representing a portal dedicated to that concept, and the applications serving various types of "items" or "content", without confronting the user with a different interface, behaviour, or data synchronisation headaches. | ||
| + | |||
| + | Now that we have a shared hierarchical context structure that is consistent across applications, we also need a global system of tags which applies across application boundaries and can be used in conjunction with the tree to filter down what is being viewed. That way we could have quite a powerful framework that not only allows hierarchies but also the more whimsical and flexible tags (known in wiki terminology as "categories"). The way the Firefox web browser organises bookmarks is an example of accommodating both trees and tags. The most popular way to display tags is as a cloud within which the most popular tags are displayed in larger font and clicking on them will lead you to a collection of every item that has the particular tag associated with it. The problem with tags currently is that you will need to create a set of tags ''for each application'' that can handle the concept and there is no way to click on a tag that will show you all items ''across application boundaries'' that have that tag. We would like to see that solved, giving us a unified navigation and filtering paradigm and allowing applications to be integrated "behind the scenes" to allow the manipulation of chats, projects, tasks, events or whatever "item" they might be providing. The [[Cynapse#Cyn.in]] application views are an elegant example of how this could be displayed: | ||
| + | |||
| + | [[File:Cynapse-application-views.jpg]] | ||
| + | [[File:Cynapse-add-content-panel.jpg|600px]] | ||
| + | === Example === | ||
| + | {| | ||
| + | |-valign="top" | ||
| + | |[[File:Mashup-tree-tags.jpg|650px]] | ||
| + | |For example, imagine you are viewing the tree of "Open Corporation" and wish to follow up on some sales opportunities. You would have selected the "Sales" branch, which gives you the sales portal in the right hand application view. In addition you select "Opportunities" in the tag cloud of "Open Corporation". Then, in the right hand pane you select "Contacts" from the items button. You now have the total amount of contacts filtered down by contacts assigned to the sales department, tagged with "opportunity". | ||
| + | |} | ||
| + | |||
| + | ;Further topics to cover: | ||
| + | *User account synchronisation and storage | ||
| + | *Smart caching of content | ||
| + | *High-level portal structure | ||
| + | *User interface and preferences | ||
| + | *Definition of objects and queries, easy creation and adjustment of such | ||
| + | *Subscription to packages of content and functionality across underlying applications | ||
| + | *Robot framework for import, synchronisation, account logins | ||
| + | |||
| + | === Record Administration === | ||
| + | One aspect of our prototype [[wiki organisation]] system has which we haven't been able to find in existing open source solutions is the ability to replicate our [[portal]] structure. It's based on the idea of extending the CMS/Wiki to allow the users to adjust their portal structure to suit their own needs using [[wiki organisation]] packages as an initial starting point. | ||
| + | |||
| + | In terms of functionality requirements of the portal structure, the foundation concept is that of ''records'' and ''record-types''. Records are sets of properties that can be associated with an article. A record-type consists of a form which is used to edit the records of that type, and a template which defines how that set of properties should look in the page. | ||
| + | |||
| + | In conjunction with this is the ability to create simple queries based on property values and resulting in a set of matching records. The results can be rendered as a table or a list, and can be further transformed by using the host CMS's templating system, for example to render the results as a select list in a form, or be adjusted to suit a javascript widget, report or chart. | ||
| + | |||
| + | Queries can be done in a user-friendly way since the templates that need to be added to an article to create them can themselves be record-types so that they're created and modified via their forms rather than difficult syntax. | ||
| + | |||
| + | This approach allows the organisation members to effectively define their own applicational structure which is a dynamic and integral part of their documentation and knowledge structure. | ||
| + | |||
| + | == Current solutions and functionality to integrate == | ||
*[[Groupware]] applications --> emails, contacts, calendars, tasks, projects and [[Group decision]]s | *[[Groupware]] applications --> emails, contacts, calendars, tasks, projects and [[Group decision]]s | ||
*Global accounts and synching via robot framework - OpenID? | *Global accounts and synching via robot framework - OpenID? | ||
| Line 9: | Line 317: | ||
**Records, forms & queries | **Records, forms & queries | ||
**Organisational setup (forms) and org. templates | **Organisational setup (forms) and org. templates | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
*[[Physical network]] | *[[Physical network]] | ||
| − | [[ | + | == Our development plan == |
| + | Beginning with being able to manipulate one tree across several applications, followed by the use of a unified set of tags across applications, using our [[Wiki Organisation]] approach, we will begin to implement the ideas outlined here. Further detail is described in the [[mashup]] article. | ||
| + | |||
| + | |||
| + | |||
| + | == See also == | ||
| + | *[[Platform roadmap]] | ||
| + | *[http://wiki.debian.org/FreedomBox FreedomBox] ''- Links about P2P security, Web of Trust, WebID, and Philosophy of Social Web'' | ||
| + | *http://federatedsocialweb.net/wiki/Projects | ||
| + | *http://lorea.cc/ | ||
| + | *[http://esw.w3.org/WebID WebID] | ||
| + | *[http://groups.google.com/group/federated-social-web Federated social web] | ||
| + | *[http://www.slideshare.net/bblfish/philosophy-and-the-social-web-5583083 Philosophy and the Social Web] ''- by Henry Story'' | ||
| + | *http://web-and-philosophy.org/ | ||
| + | *http://www.ibiblio.org/hhalpin/homepage/thesis/ | ||
Latest revision as of 13:07, 12 July 2015

This specification describes what is required for setting up a platform, an organisation designed to form a network of completely independent nodes with other platforms, which we call the platform network. The high-level conceptual development path for platform technology is described here. We will describe our requirements and use cases in order to determine the correct components to use for various aspects. These requirements are based on our research over the past ten years or so regarding what is required for a decentralised, robust and efficient solution to maximise personal empowerment, freedom and privacy and allow for the emergence of bottom-up and grass-roots solutions, and organisations, based on the needs of the people. In our manifesto we describe the principles and values that guide our work and are foundational to these specifications, in particular the four criteria:
- Openness
- Completeness
- Think Global, Act Local
- All Aspects Changeable
The document specifies the way to build a powerful and flexible web framework that will empower the vision
The development group requires an independence-focused and philosophically aligned build partner to develop its platform. The development group has elected OD as the ongoing architectural consultants for the development of the development group application. Our initial involvement prior to any funding is to produce a specification document that outlines the work to be done, and the general scope of that work. This document includes that specification and scope of work. This document can also serve as a technical basis for investment pitches to source funding for the process of constructing a more detailed specification and finding developers. We've divided the software aspects of the project into the following four general levels, which can all be developed in parallel, and which clearly delineate the public aspects from those controlled by the development group.
The most important thing to get clear with respect to the business relationship from OD's perspective is that everything we're developing is free, unrestricted open source software licensed under GPL. The aspects not under this license are the development group business rules and branding which are content in the system, but are not components of the system itself. This specification is focused on the foundation environment inside, upon which the the development group business rules and branding will be built. The section below defines the delineations between OD and the development group more clearly.
The foundation environment: This is the network application environment. An object-wiki in a peer-to-peer semantic network and a set of foundation objects defining the basic common organisational concepts, relationships and processes.
The application interface: This is formed from content, such as templates, documentation and processes. It allows everyday users to build, refine, share and collaborate on their documentation and organisational systems. It even allows people to adjust and share their own custom applications in the environment.
Contents
Overview
The Software

This section provides an overview of the software application. We're introducing TheBrain application here because it shares a lot conceptually with the interface we plan to develop, if you're unfamiliar with TheBrain, see this blog post for a quick introduction to the concept first.
To the right is an image of TheBrain which is essentially a graphical concept and relationship mapping tool. It's very similar to a mindmapping tool, except that it's more node-oriented which allows more intuitive navigation around large complex structures of nodes and for diverse concepts to be connected more easily.
Nodes
The application is focused on one particular node in the network at a time which is always at the centre of the screen. The user can move the focus to other nodes by following the linked relationships. Each node may act as a storage repository for information relating to its concept, for example a node representing a particular idea may contain notes, photos, website links and other related items.
Viewers
The application is like a window, or "viewport" looking into the structure of nodes. The term "viewer" is used to refer to the general class of applications which allow users to view and edit collections of data. The viewer is a tool to provide a window onto the data set and allows the user to look at the data from different perspectives called "views". The idea of moving the "current focus" around the data set (in this case nodes) is a common feature of viewer applications.
Since nodes can be filled with associated content such as text notes and files, it's useful for the viewer application to allow easy switching between a number of different ways of looking at the node currently in focus. For example a "document view" would present the text-based aspects of the current node in a document format, or switching to "file view" the same node would appear as a collection of file attachments in a file-browser like way.
The main point here is that the viewer offers a number of unique views onto the current node which can be switched between at any time. Each view renders particular aspects of the current node and offers navigation methods appropriate to that kind of view for navigating the viewer to other nodes. The nodal view shown in the image of TheBrain to the right is just one view of many that could be added to the viewer application.
Semantic networks & Ontologies
The nodes that make up the data structure in TheBrain are called "thoughts" because the network of relationships is composed completely of the user's own concepts and ideas. In our application, nodes will be objects in the object-oriented (OO) sense, and the relationships connecting nodes together will also be objects making the resulting structure a semantic network. This commonly used structure can be stored or communicated in a wide variety of formats such as OWL which is supported by TheBrain.
If all the nodes in the semantic network are objects, the structure can not only contain arbitrary "thoughts", but also high-level functionality such as processes, tools and interface elements. We will also make use of object-oriented concepts such as inheritance so that objects can be based on others and adjusted for more specific needs.
These semantic structures of objects that offer not only organised information, but also collections of tools with which to access it are called "ontologies". The name "ontology" is used because it concerns reality rather than being just a "taxonomy" which is passive categorisation.
Our ontology
We will create an ontology of content that will form the foundation structure of the network. This will be the initial high-level data set that the viewer application provides access to. We've designed a basic "template organisation" structure.
In any project or organisation the total number of members are always able to be divided into a hierarchy of sub-groups such as departments or roles. This hierarchy is always changing hence we use the term "organic group", because although many of the groupings are very static like the departments and roles, some of them undergo more change, such as members of particular projects or people sharing a common interest. We use the term "ontology" instead of just "hierarchy" or "taxonomy" because this structure of groups reflects the high-level reality of the organisation at any given time.
Each group has it's own home page, or "portal" which is tailored specifically to the needs of its members, firstly by being based on a template appropriate to the type of group it is (such as a department or a project), and secondly because it is easy for members to collaborate on what their portal should look like and which tools and resources should be available to them. Wikipedia's "Enterprise Portal" article is a good place to go for general information about this kind of portal.
Some common tools used by such groups are blogs, forums, wiki pages, mailing lists, group decision-making tools (such as polls), project management tools, shared schedules, resource booking systems and online chat systems.
The workflow interface

We will develop a simple graphical means of defining workflow, we are calling this the 'workflow' view. The 'workflow' view will show sequences of actions separated by intervals or events. An example workflow could be the events occurring as a form is passed around various roles each making changes to the content. This "workflow interface" needs to be simple enough to be used every day by normal users, but complete enough to cover all the organisation's use cases.
Network of groups
We call our semantic structure of objects an ontology because it describes functional systems which will represent real-world processes and resources. We intend for all the running instances of the application to form together into a peer-to-peer network containing a single coherent semantic network of objects. Each running instance of the application will be a viewer onto the single shared data-structure.
This is not to say that all information in the network has to be viewable by all. The idea is that all the peers contribute to the serverless persistent object environment, but users and groups will be able to work with permissions and encryption in the usual ways to have privacy where they need it.
The Architecture
Our application requirements are relatively straightforward and could be built simply by extending an existing Content Management System such as Drupal or Plone, since they already have all the functionality we need apart from the workflow interface discussed in the previous section. However, the back-end of this platform has a number of unique features such as self-containment and decentralisation in order to conform to our manifesto, which make these existing platforms inappropriate.
Open
Open source is a set of principles and practices that promote access to the design and production of goods and knowledge[1]. The term is most commonly applied to the source code of software that is available to the general public with relaxed or non-existent intellectual property restrictions. This allows users to create software content through incremental individual effort or through collaboration.
The word "open" in the phrase "open source" means much more than simply making the source-code available to the public. It includes the processes involved in collaborating on the source and in implementing and using the end product. When it comes to open source business, the "source code" means the business system and requires a complete definition of all operations of the business and must include the ability to collaborate on that system and allow interested parties to implement and use the same system themselves, and refine it not their specific needs.
Self contained
The core, network and interface need to be self contained, that is, defined in their own terms. The project then evolves from its own tools and can progress effectively due to the reduced need for specialists.
Total self-containment isn't possible currently since the application relies on aspects defined outside of itself, such as the the language it's programmed in and the operating system. Eventually we hope that even these things would be able to be moved into the network and developed from within it, but for this initial phase of development, having just the workflow systems and our own documents, development and project management inside the system is acceptable.
Some technologies support the concept of self-containment more readily than others, for example, the Squeak language and development environment is all defined in it's own objects and syntax. Such technologies are very good candidates for us to use to build our system within even though they are less popular.
Mesh compliant
The importance of independent communications is clearly demonstrated by the recent events in egypt[2]. Having meshing capable applications offers new possibilities for robustness and resilience in communications, but this is discussed in more detail elsewhere.
We don't deal with meshing directly, the point is that our software is able to synchronise changes over whatever transport mechanisms are available whether it be Internet, wireless meshes, point-to-point links or even physical media such as portable hard-drives and memory sticks.
The software needs to be peer-to-peer so that groups can still work together seamlessly even when they are disconnected from the larger network. For example, a group working together in an office which temporarily has an Internet outage could still keep collaborating and communicating effectively without errors. As soon as the network re-establishes itself, all the differences that have accumulated between the local group and the larger network begin synchronising. In the case of conflicting updates, workflows are created amongst the relevant participants so that they will be eventually resolved.
Although this is a more complex infrastructure to design, the result is ultimately more efficient because it eliminates the "rush hour" effect.
More detail for developers
The Software
The Unified Ontology
A shared and unified network of groups, all having their own extensions of the ontology which together form the unified ontology. Our system includes an initial set of content - content containing thousands of objects such as departments, roles, procedures, and relationships. This provides a unified and immediately useful framework to begin building content into.
The network viewer application
The application:
- is a browser based viewer onto the unified ontology
- has an address (running the browser) that resolves to localhost
- has a standard graphical interface with various views to select the object layer containing personal preferences, toolbars, views menu, content area and probably a navigation area
- has standard MVC style views onto the data structure including text, files, forums, documents, blogs, files, nodal-network (including workflow)
Foundation Ontology
Object Oriented The network is composed of many instances of the software called "peers", and together all these make up a logical network of nodes that form objects and relationships. The objects have basic object-oriented relationships such as "parent", "sibling", "ancestor", "descendent" etc.
Nodal reduction and events
Instantiation workflows
Collaborative ontology
As per the Organic Design principles, the overall environment will be a "portal ontology" based approach. But there are also a number of lower level classes such as those mentioned above, "job", "task", "activity". To ensure that the ontology is able to scale up to any complexity of organisational system in the future (to allow for our ultimate plan of the people taking large-scale organisation into their own hands), we need to use a proven set of foundation classes. We've chosen to use the ERP5 classes for this since they closely match our own "Nodal Model" but yet also have been extensively proven across many large-scale organisations already.
These five core classes/concepts are Node/Context (such as a person, an organisation, a warehouse, a bank account), Resource (a class/kind of tangible or intangible resource, transferred between Nodes in business processes, e.g. a product, a raw material, a service, cash etc), Movement/Exchange (ordering, deliveries, accounting transactions, payments, manufacturing processes), Item/Record (an instance of Movement), which may have a special identification such as a barcode, an RFID, a subscription, a ticket, etc) and Path/Workflow (a possible Movement that is useful to define trade conditions, supply conditions, payroll models).
The workflow interface
The One Big Voice system involves around twenty different roles each with their own procedures, which results in a complex application. However, when looking more closely at the functional requirements of these procedures, a common pattern emerges. All of them are sequences of events and notifications that could all be described with a common workflow mechanism, reducing most of the application complexity into the domain of content.
Furthermore, when we look at the requirements for the ActionBuilder tool, which is used to define milestones and associated actions, we find that the same workflow interface would be appropriate for this too. The only difference is in the events and actions that should be available in each context.
A graphical nodal system allowing nodes to be arbitrarily created, copied, moved, linked together and contained, would form an excellent basis for a generic workflow interface. These nodes could then be individually selected and set to a pre-defined workflow class, or be refined by allowing events and associated actions to be added, removed or modified. The events and actions available would depend on the context, the class of the node being refined, and on the role of the user.
"Jobs" are instances of workflow classes and should be viewable in the system, each having a "status" property. The status of a job would initially be "pending" if it is created but has requirements such as roles or resources not selected. When all the requirements are satisfied, the status changes to "in progress." When they're complete, their status changes from "in progress" to "completed." They should also be able to be "cancelled" or "on hold." Since workflows can be nested, the job instances should be viewable as a tree.
Project management can be achieved using this workflow system and can be designed like existing effective project management platforms.
Network of groups
A group of people who all trust each other. People can belong to many trust-groups, and all the trust-groups together compose the platform network which is a network formed from trust relationships. Information is able to pass safely and securely between any two people in such a network because the route can be divided up so that information only ever passes between people who trust each other.
Group types - There should be different types of Organic Groups that all work the same way, but have specific layouts and collections of tools. Such types represent the major concepts such as Organisation, Role, Project or Campaign. As well as acting as a container for tools and resources and exhibiting various members, these groups should also have their own data fields and views so that they can be searched for and accessed from various contexts.
Collaboration - The tools that are selected and the way they're laid out should be able to be published as a template option so that it's an available option for others to use. These options should be able to be searched by popularity and other properties so that people can see which portal methodologies are being most widely used within particular contexts. Publishers should be able to include notes about their decisions so that others can make informed decisions when selecting from available options.
Splitting and merging - Groups should be able to divide in separate groups, or merge multiple groups into a single group, as well as be able to create sub-groups. For example if a group decision is unable to be resolved, the group could split into two, or a group representing an organisation may wish to create sub-groups representing various departments and further into projects or roles. Note that roles are a separate concept, but roles may like to have an Organic Group for themselves as a common portal catering to their specific needs.
The Architecture
Open
Before a system is able to undergo change through feedback it must first be open. For things to evolve and refine through the scientific method they must be open and reproducible.
Self contained
A self contained system is simply one that can be developed and improved from within itself. Being reliably complete and independent it can be deployed as a package that's ready to install and operate fully. This self contained system, functioning even while isolated from other networks, can grow, expand and deploy it's own system to form new groups. This is achieved in practice through the availability of software packages containing the system that can run on any device, such a tablets, smart phones or laptop computers.
Members can deploy the system for new groups without needing any information from outside their own group, because the entire system is locally available in every implementation, and can be cloned easily onto standard media.
Self containment includes features such as;
- All aspects are changeable using collaborative processes.
- Easy deployment since all the necessary build and education tools are included.
Organisational Model
A system for project management, time accounting and invoicing, communications and scheduling are formed from a collection of workflows (both applicational and human processes) involving the foundation ontology classes. These aspects are all done the standard ways using the usual objects/forms and protocols.
One important aspect in which our organisational model differs is in the utilisation of a generic scalable way of dealing with resources. If people are using the system to specify everything's where-when, then there should be a generic method of multiplexing that work onto the transport system. This same method could apply to files over TCP, or to the movement of physical items in bags and cars. The first step is in assessing the workload and then deciding how it should be distributed across schedules and routes.
Mesh network
Querying and Job execution
To avoid potential flooding of the network with query requests from many peers, queries need to be thought about in a different way. Think of a query as being created in a portal by the subscribers to the portal, and being the result of a workflow which requires the input of each member before it can obtain a result. The query is given an "update cycle" and then all members are required to make their updates to the result before the next update cycle. The published result of the query always remains the same until the end of the update cycle.
Workflows can be scheduled such that all members will make their updates at different times that are distributed evenly over the update cycle period. This principle can work just as well for internal queries that involve classes and instances rather than real members; each class acts like a portal of information shared and collaborated on by its instances. When lists of members or instances become too large, a natural division by region should occur with larger regions having larger update cycles, and having the smaller regions as their member instances.
Queries done in this way require all the possible resulting instances to add an event. This raises potential permission issues, so needs to be handled with care. An application can use energy from all the peers that instantiate it, but the information the application can make use of within those instances is determined by permissions. In the case of One Big Voice, the queries created in the site itself would only involve One Big Voice properties, and One Big Voice would set the permissions of properties it creates even those in the context of user objects. The One Big Voice application would ensure that a useful range of aggregated and state-based information be available to user queries and tools like the ActionBuilder.
Queries that are built within specific groups portals or in the context of a campaign can make use of already available statistics and state information, but any new queries they create that require instantiation of events cannot be made on spaces outside their own context. In other words, members of a group can only make queries that have results that are objects within that group. To go beyond requires that only existing available query results be used.
Queries of this type are actually regular reporting jobs. This principle applies to all kinds of jobs as long as they are linearisable which means that they can be broken up into an arbitrary number of equal portions of work. In the same way that all the members of a query are scheduled to make their contribution to the result before the next update cycle, so could members also be delivered a package of work needing to be completed and results filed within a specified window of time.
The workload for a context increases in proportion to the number of instances, because every member or user of a context supports an instance of that context. This means that the ability to perform work increases along with it and as a result the network always stays in balance.
This method of job distribution can scale up to human process too, such as painting signs prior to a march.
The Build
We will pursue a development approach that involves us implementing these specifications with a team of developers and managing that team to achieve the milestones listed below. Once Organic Design has had the Development specification signed off by One Big Voice and funding has been secured, we will begin a process of identifying suitable development teams and soliciting proposals from those teams for implementing the specification. The methodology we will use for implementation and the milestones for development are outlined below.
Team and Technology Selection
This process also includes identifying and interviewing teams of developers (Request for Proposals - RFP), who will submit proposals for how they intend to meet the development milestones and how much they will charge for the milestones outlined here. Therefore we will satisfy two goals at once, the selection of a team and the completion of the specification document, using the feedback of the developers to evolve it.
The selection of an effective project management framework and establishing appropriate PM processes and documentation in preparation for the development work beginning is the second key part of this project. It makes sense to review and test, select and then customise the project management framework as the document is brought to a code-ready state with the assistance of the feedback from developer teams. The test of how successful this process has been is whether it is possible to fully contain the milestones and processes being discussed in the specification document within a functioning system that can support a project team's development activities.
We are assessing a number of suitable development platforms. These will support the Agile methodology in general and fulfill our more specific requirements, such as accounting for time and cost.
Issues affecting the Technology Decision
Workflow: The development time will be greatly reduced if we can select a technology that strongly supports the workflow paradigm since the majority of our application is workflow oriented.
Peer-to-peer: It's imperative that the system be running in a peer-to-peer architecture by the time it starts gaining popularity since many campaigns in the system will be very controversial and the risk of the system being shut down may force us to compromise on our agenda-free stance. Conversely if at the time these threats become apparent we have a critical mass in peer-to-peer space it will cause the system to gain popularity even faster if we can report such threats to the members and show them how to spread the peer-to-peer accessibility.
The technology selection phase should be looking closely at each candidate technology's ability to work in the peer-to-peer space. So far only Squeak and Java are the only two environments we've found that have complex applications running in a truly peer-to-peer space, and we have a strong aversion to using Java for a number of reasons, both technological and philosophical.
Prototype: If we decide that a fully peer-to-peer model is going to take longer than six months to develop to a level of initial usability, then we'll need to seriously consider the development of a prototype system in an environment that allows us to get up and running more quickly.
Migration: If we were to go with a prototype system first, then we have to ensure that we are developing a migration scheme along with the peer-to-peer system as we develop it.
Scalability: The architecture needs to ensure that the system can scale indefinitely. Part of this involves ensuring an independent reproducible aspect to the system so that different regions can be managing their own affairs and be responsible for their own resource. If the system is fully peer-to-peer, then scalability shouldn't be an issue and such regional (and also class-based) partitioning will be inherent. But if we go the route of developing a non peer-to-peer prototype system first, then even this must scale reasonably well. Our research has shown that Drupal is capable of scaling well enough, and can be handled as it's needed.
Developer conversations
We have started discussion threads in a number of developer mailing lists to get an idea of how the development teams behind some different candidate technologies felt about our project and how their technologies fit in with it. We have already contacted developers to ask them about certain facets of the development work. They are contributors to the following projects: Joomla, Drupal, Plone, Zope, ZODB, NEO, OpenCobalt, Squeak, Seaside, Pier.
Personal Platform
Beginning with the relevance to the individual, the platform is a software package that enables the user to organise his or her own life, to maintain an overview of goals, values, tasks and commitments, much as described by the GTD movement, for personal organisation. In addition, we require communications tools and common office productivity software such as email and schedule, web browser and an office suite. These needs are rounded off by online private and secure file storage services to ensure backup of vital data and synchronisation across multiple devices.
This can all be done now...
Now these things taken individually are nothing special, anyone can choose to set up a computer with a free or paid-for operating system, such as Linux, Apple or even Windows, then install free or paid-for applications to achieve office productivity and personal organisation requirements, followed by setting up online user accounts to access services and even applications in the "cloud". However, there are a number of limitations that become The development groupious when currently trying to fulfil even these basic personal requirements using off-the-shelf software available on the market today. Without going into full detail, the key issues are:
Fragmentation of data and user accounts

|
This toolbar along the bottom of a blog article allows people to share the information using their favourite service, possibly several services. Each of these services would have a separate log in and separate data such as user profiles that will need to be kept up to date. |
Restriction of freedom and loss of data privacy

|
Who has time to read through all that boring legalese, just to set up an account or install some software? Unfortunately it turns out that some terms and conditions are anything but reasonable, claiming ownership and perpetual use of all of the data you upload or share on that service. |
Having to pay for proprietary software

|
Use a lot of online services? Those costs can add up, not to mention being prohibitively expensive in so-called "emerging markets". |
Lack of offline synchronisation with most cloud services

|
Got no Internet? Tough, if your e-life is in the cloud. Most services don't allow for easy offline synchronisation. |
Freedom in The Cloud
| For more information, mainly on the aspect of privacy and the impact of the centralisation of data on our freedom, view Eben Moglen's talk that inspired the creation of a unified, private open source alternative to Facebook and similar services: Diaspora. |
What we want instead
In contrast, what platform offers is an integrated, consistent user interface, with the context being navigated comprising the users areas of interest and personal projects, rather than fragmented applications. We envisage a fully packaged installation file (ISO) that allows an operating system to be set up from scratch on any device, offering a web browser interface to allow the user to define their areas of interest and projects, import legacy data and access any applications as required to do work or just socialise online.
The Platform is a self-contained solution that could for instance run on a laptop, whether or not there is Internet available, which could fetch updates, messages or files as and when connectivity is available. Imagine having one place from which everything is managed, messages and updates are sent from, a private, secure online home with a unified inbox, set of files, bookmarks, documents, contacts, to be easily shared, in a system that just works and is completely self-contained.
The good news is that this is all possible now, by way of integrating existing open source technologies using the right kind of "glue". Further on we will identify our current candidates for fulfilling various aspects described here.
Platform Organisation
Note to be worked on:
Provides easy to use function to share video and audio media that provides education about deploying and growing the seed. Media can be tagged in the wiki record, to offer a thumbnail view to relevant shorter media clips. This provides a tag-able, contextualized sharing of media section-by-section.
The platform media library becomes micro-clipped, tagged and able to be be used and shared at a very granular level throughout all platform communications.
One tree that holds it all together
The framework platform is based upon can be thought of as a "glue" that integrates a number of existing technologies and allows new technologies to be integrated as they become available. At the interface level, a tree represents the ontology of the user or organisation being viewed. This tree is a meaningful and coherent structure that represents a small number of top-level concepts. The tree will be different when looking at one's personal "electronic life representation", in which case it consists of "areas of focus" in life, as opposed to viewing a shared organisational tree. David Allen coined that term and recommends having a perspective on life (20.000ft) at which only these areas of focus are visible in order to assess how much time one is spending in different areas and whether they are in balance. This area is in between the most high-level aspects, such as goals, vision and values and the more concrete day-to-day aspects such as projects, checklists and tasks, which would typically be associated with one or more areas of focus. On the level of organisations, this concept maps quite directly to what is normally called a "department" or "division".
- Some example tree structures for personal organisation and business

David Allen, creator of GTD, shows his company "areas of focus"/departments in this tree
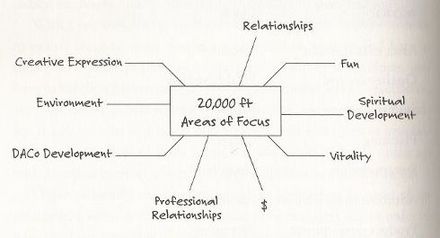
David Allen's personal organisation areas of focus
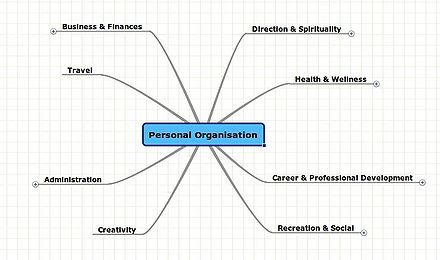
A personal organisation tree done with mindmap software



As you can see from the examples, the structure can be quite simple and encompassing at this level.
Our goal is to enable such a tree to replace any hierarchical navigation structures being used by existing applications, such as the folder trees of email programs, file managers or bookmarking programs. Instead, the personal or group organisation tree will be created once, using a simple, forms based process, then linked to applications. This will then allow one structure to be navigated and added to within a consistent interface, with each area of focus or department representing a portal dedicated to that concept, and the applications serving various types of "items" or "content", without confronting the user with a different interface, behaviour, or data synchronisation headaches.
Now that we have a shared hierarchical context structure that is consistent across applications, we also need a global system of tags which applies across application boundaries and can be used in conjunction with the tree to filter down what is being viewed. That way we could have quite a powerful framework that not only allows hierarchies but also the more whimsical and flexible tags (known in wiki terminology as "categories"). The way the Firefox web browser organises bookmarks is an example of accommodating both trees and tags. The most popular way to display tags is as a cloud within which the most popular tags are displayed in larger font and clicking on them will lead you to a collection of every item that has the particular tag associated with it. The problem with tags currently is that you will need to create a set of tags for each application that can handle the concept and there is no way to click on a tag that will show you all items across application boundaries that have that tag. We would like to see that solved, giving us a unified navigation and filtering paradigm and allowing applications to be integrated "behind the scenes" to allow the manipulation of chats, projects, tasks, events or whatever "item" they might be providing. The Cynapse#Cyn.in application views are an elegant example of how this could be displayed:


Example

|
For example, imagine you are viewing the tree of "Open Corporation" and wish to follow up on some sales opportunities. You would have selected the "Sales" branch, which gives you the sales portal in the right hand application view. In addition you select "Opportunities" in the tag cloud of "Open Corporation". Then, in the right hand pane you select "Contacts" from the items button. You now have the total amount of contacts filtered down by contacts assigned to the sales department, tagged with "opportunity". |
- Further topics to cover
- User account synchronisation and storage
- Smart caching of content
- High-level portal structure
- User interface and preferences
- Definition of objects and queries, easy creation and adjustment of such
- Subscription to packages of content and functionality across underlying applications
- Robot framework for import, synchronisation, account logins
Record Administration
One aspect of our prototype wiki organisation system has which we haven't been able to find in existing open source solutions is the ability to replicate our portal structure. It's based on the idea of extending the CMS/Wiki to allow the users to adjust their portal structure to suit their own needs using wiki organisation packages as an initial starting point.
In terms of functionality requirements of the portal structure, the foundation concept is that of records and record-types. Records are sets of properties that can be associated with an article. A record-type consists of a form which is used to edit the records of that type, and a template which defines how that set of properties should look in the page.
In conjunction with this is the ability to create simple queries based on property values and resulting in a set of matching records. The results can be rendered as a table or a list, and can be further transformed by using the host CMS's templating system, for example to render the results as a select list in a form, or be adjusted to suit a javascript widget, report or chart.
Queries can be done in a user-friendly way since the templates that need to be added to an article to create them can themselves be record-types so that they're created and modified via their forms rather than difficult syntax.
This approach allows the organisation members to effectively define their own applicational structure which is a dynamic and integral part of their documentation and knowledge structure.
Current solutions and functionality to integrate
- Groupware applications --> emails, contacts, calendars, tasks, projects and Group decisions
- Global accounts and synching via robot framework - OpenID?
- Personal portal and broadcast centre
- CMS
- Content (procedures, roles, etc.)
- Ontology portals structure
- Records, forms & queries
- Organisational setup (forms) and org. templates
- Physical network
Our development plan
Beginning with being able to manipulate one tree across several applications, followed by the use of a unified set of tags across applications, using our Wiki Organisation approach, we will begin to implement the ideas outlined here. Further detail is described in the mashup article.
See also
- Platform roadmap
- FreedomBox - Links about P2P security, Web of Trust, WebID, and Philosophy of Social Web
- http://federatedsocialweb.net/wiki/Projects
- http://lorea.cc/
- WebID
- Federated social web
- Philosophy and the Social Web - by Henry Story
- http://web-and-philosophy.org/
- http://www.ibiblio.org/hhalpin/homepage/thesis/







{kind=link}